1 Neuerungen des Headers im neuen Internet-Protokoll IPv6
1.1 IPv6-Header
Der IPv6-Header (Abb. 1.2) wurde gegenüber
dem IPv4-Header (Abb. 1.1) wesentlich geändert, so daß es zweckmäßig
erscheint, die einzelnen Felder eingehend zu besprechen (siehe auch [RFC
1883]):
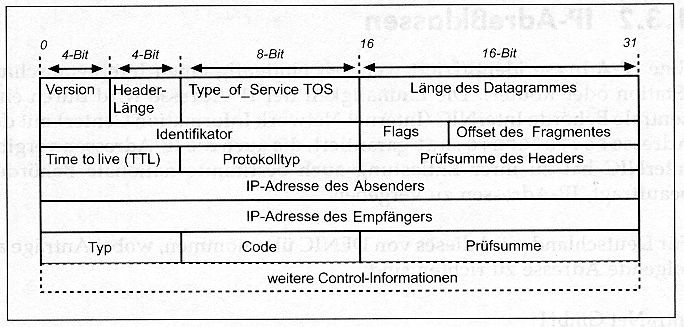 Abb. 1.1: Struktur des Ipv4-Headers
Abb. 1.1: Struktur des Ipv4-Headers
 Abb. 1.2: Struktur des IPv6-Headers
Abb. 1.2: Struktur des IPv6-Headers
Die Version
ist 6.
Im Feld »Priorität«
kann der Sender einem Paket 16 Prioritäten zuordnen. Ein Teil dieser
Prioritäten ist bereits für zwei verschiedene Gruppen von Anwendungen
reserviert:
1. Für »klassische« Anwendungen ohne
Real-Zeit-Anforderungen, wie News, E-mail, Dateitransfer, Datenbankzugriff
und Internetsteuerpakete. An diesen Anwendungen werden im allgemeinen keine
Real-Zeit-Anforderungen gestellt. Der Kontext der höheren Priorität
bedeutet, das Paket möglicherweise schneller zu bearbeiten. Zum Beispiel
sollte der interaktive Verkehr des Telebanking (Priorität 6) bevorzugt
gegenüber den Paketen der elektronischen Post (Priorität
2) übertragen werden (Tab. 1.1). Ferner können diese Prioritäten
zur Flußkontrolle verwendet werden. Im Fall eines Staus werden nur
die wichtigeren Pakete (d. h. diejenigen mit höherer Priorität)
bearbeitet. Die Pakete mit niedrigerer Priorität werden verworfen
und entsprechend der Flußkontrollenstrategie zu einem späteren
Zeitpunkt übertragen.
|
Priorität
|
Typ der Übertragung
|
|
0
|
nicht charakterisierter
Verkehr |
|
1
|
Füllverkehr
(z.B. News) |
|
2
|
unabhängige
Datenpakete (z.B. E-Mail) |
|
3
|
(reserviert) |
|
4
|
abhängige
Pakete größerer Datenblöcke (z.B. FTP, NFS) |
|
5
|
(reserviert) |
|
6
|
interaktiver
Verkehr (z.B. Datenbankzugriff) |
|
7
|
Internet Steuerverkehr
(z.B. SNMP) |
Tab. 1.1: Aktuelle Prioritäten für Anwendungen
ohne Real-Zeit-Anforderungen
2. Für die Anwendungen mit Real-Zeit-Anforderungen
werden die Prioritäten 8 bis 15 verwendet. Diese Prioritäten
erlauben dem Sender, die Wichtigkeit der Real-Zeit-Ströme zu bestimmen.
Solche Anwendungen stehen vor allem mit Multimedia wie Live-Audio und LiveVideo
in Verbindung. Diese Prioritäten werden bei der Implementierung von
Mechanismen für Flußkontrolle (network scheduling) und der Prozeßverwaltung
(process scheduling) entlang des multimedialen Stromes gesetzt.
Das Feld »Flow
Label« identifiziert einen Strom (flow), d. h. eine Kette
von zusammenhängenden Paketen mit gleichem Sender und gleichem (Unicast-
oder Multicast-) Empfänger, die von den Routern gesondert behandelt
werden sollen. Diese gesonderte Behandlung könnten z. B. Garantien
für QoS (Quality of Service, Dienstqualität) oder für Real-Zeit-Verkehr
sein. Die Art dieser Behandlung kann explizit über ein spezielles
Protokoll (z. B. das Reservierungsprotokoll RSVP für Multimediaströme)
oder durch die Pakete mit diesem Flow Label selbst erfolgen. Ein Beispiel
des letzteren wäre die Nutzung des Hop-by-Hop-Headers um spezielle
Steueraktionen zu initiieren.
Das Feld ist 24 Bit lang. Es war ursprünglich mit
dem Feld »Priorität als Identifikator des Stromes (Flow ID)«
gedacht. Das Flow Label ist eine pseudo-zufällige Zahl (zwischen 1
und FFFFFF), die in Kombination mit der IP-Adresse des Senders einmalig
ist. Alle Pakete eines Stromes müssen die gleiche Sender-Adresse,
Empfänger-Adresse, Priorität und Flow Label haben. Der Wert 0
bedeutet, daß kein Flow Label genutzt wird. Ein Flow Label wird von
einem Router entsprechend der zuvor vereinbarten Aktion interpretiert oder
ignoriert, falls der Router Flow Label nicht unterstützt.
Das Resultat dieser Aktion kann in einem Cache gespeichert
werden, so daß die nachfolgenden Pakete dieses Stromes es erneut
nutzen können. Das Flow Label kann dann als Schlüssel zum Hashing
des Cachespeichers bei den Routern genutzt werden. Falls die Art der Behandlung
jedoch nicht explizit spezifiziert ist, kann der Router bei einem gültigen
Flow Label (unterschiedlich von 0) sie selbst festlegen. Diese Aktion kann
auch für die Dauer von maximal 6 Sekunden ge-cached werden.
Das Feld »Payload-(»Nutzlast«)-Länge«
bestimmt die Länge (in Byte) des Rests des Paketes nach dem IPv6-Header.
Wie das Feld »Paketlänge« in IPv4 wird es mit 16 Bit kodiert,
was einer maximalen Paketlänge von 64 KByte entspricht. Im Gegensatz
zu IPv4 wird nicht die Länge des Datagramms, sondern nur der Rest
nach dem Header erfaßt. Zum Übertragen von 1 000 Byte Nutzdaten
wird z. B. die IPv6-Payload-Länge 1 000 sein, und die IPv4-Datagramm-Länge
1020. Die Jumbo-Payload-Option bei IPv6 erlaubt es aber, die Länge
eines Datagramms mit mehr als 16 Bit zu kodieren, d. h. längere als
64 KByte Datagramme zu Übertragen (siehe Abschnitt 1.2.2).
Das Feld »nächster
Header« (1 Byte) spezifiziert den Typ des Headers nach dem
IPv6-Header. Im Gegensatz zu IPv4 ist der Typ des nächsten Headers
nicht immer TCP (Code 6) oder UDP (Code 17). Das IPv6 sieht die sogenannten
Erweiterungs-Header (Extension Header) vor, die nur dann in das Feld »nächster
Header« einbezogen werden, wenn sie gebraucht werden. Beispiele solcher
Header sind der Routing-Header (Code 43), Fragment-Header (Code 44), Authentication-Header,
etc..
Das Feld »Hop
Limit« stellt eine Korrektur des TTL-Feldes (Time-to-Live)
bei IPv4 dar. Ursprünglich sollte der Sender die Lebensdauer eines
Paketes TTL in Sekunden bestimmen. Dies wurde aber nie richtig genutzt.
Vielmehr wird ein TTL-Feld eines IPv4-Datagramms bei jedem Router (d. h.
bei jedem Hop) um eins verkleinert, bis es Null wird. Dann wird das Datagramm
annulliert, so daß Datagramme mit fehlerhaften EmpfängerAdressen
nicht ewig über das Internet irren. Mit anderen Worten wurde TTL schon
immer als einer Art »Hop Limit« genutzt, so daß die Namensänderung
bei IPv6 zu mehr Klarheit beiträgt.
1.2 Optionale Erweiterungs-Header statt Optionen
Wie bereits erwähnt, stellen die Router die Zwischenknoten
der Internet-Kommunikation dar. Ihre Leistungsfähigkeit ist deshalb
von besonderer Bedeutung. Der Aufwand der Bearbeitung eines Datagramms
hängt aber davon ab, ob es standardmäßig weiter geroutet
wird oder eine zusätzliche Fragmentierung oder Behandlung der Optionen
erforderlich ist. Die Optionen in IPv4 bestimmen die gesonderte Bearbeitung
des Datagramms von den Routern oder im Endknoten. Beispiele hierfür
sind Optionen für Schutz und Sicherheit, für Routing nach einem
vorgegebenen Weg (Source Routing), für Setzen von Zeitstempeln, etc.
Die heutigen Router sind bemüht, im Standardfall
eine höhere Leistung aufzuweisen. Deshalb wird eine Art Scheduling
bei den Routern ausgeführt, indem die Standard-Datagramme ohne Optionen
bevorzugt bearbeitet werden. Auch wenn die Optionen für den Empfänger
bestimmt sind, wird das Datagramm in den Routern aufgehalten. Dies hat
andererseits die Programmierer von Internetanwendungen gezwungen, keine
IP-Optionen zu nutzen und ihre Funktionalität über höhere
Protokolle zu implementieren. Aus der Sicht der Protokollarchitektur bedeutete
das einen zusätzlichen Overhead, der aber durch die schnellere Bearbeitung
von Standard-Datagrammen in den Routern kompensiert wurde.
IPv6 löst dieses Problem durch optionale Erweiterungs-Header
nach dem IPv6-Header mit folgenden Merkmalen:
-
Nur einer der Header, der Hop-by-Hop-Header, wird (wenn überhaupt
präsent) von jedem Router bearbeitet.
-
Die restlichen Erweiterungs-Header werden nur von den Endknoten
bearbeitet, so daß keine Verzögerung durch die gesonderte Behandlung
in den Routern entsteht. Es ist allerdings zu vermerken, daß der
Source-Routing-Mechanismus mit dem Routing-Header bestimmte Router als
Endknoten betrachtet.
-
Ersetzen des Fragmentierungsfeldes im IPv4-Header durch Fragment-Header
und die Optionen durch den optionalen Erweiterungs-Header. Dadurch sind
die Router nicht mehr verpflichtet, diese Felder zu bearbeiten, was eine
weitere Entlastung bedeutet.
1.2.1 Aufbau der Erweiterungs-Header
Die Erweiterungs-Header sind optional, sie werden jedoch
miteinander verkettet: jeder Header gibt den Typ und den Abstand (Länge
des Erweiterungs-Headers) zum nachfolgenden an (Abb.
1.3). Der Typ des Headers im Feld »nächster Header«
(Abb. 1.2) wird als Codewert in [RFC
1700] definiert. Die Header-Typen für IPv4 und für IPv6 stimmen
in den meisten Fällen überein.
Die Erweiterungs-Header können auch semantisch miteinander
verbunden sein. Zum Beispiel kann eine Berechnung durch einen Header initiiert
und durch die Berechnungen eines nachfolgenden Headers fortgesetzt werden.
Deshalb ist die Reihenfolge der Erweiterungs-Header nach dem IPv6-Header
wichtig und wird bis jetzt wie folgt festgelegt:
-
Hop-by-Hop-Options-Header:
Nur dieser erste Header wird, falls vorhanden, von jedem
Router behandelt. Bis jetzt wird nur die Jumbo-Payload-Option vorgeschlagen,
die es erlaubt, die Länge eines Datagramms mit mehr als 16 Bit zu
kodieren.
-
Fragment-Header:
Der Fragment-Header wird nicht von den Routern berücksichtigt
und dient nur zur Übertragung von Fragmentierungsinformation zum Empfänger.
Er unterstützt dadurch eine Fragmentierung der größeren
Pakete nur durch den Sender. Der Sender soll demzufolge die kleinste MTU
(Maximum Transmission Unit) auf der Route kennen, um die Größe
des Fragments einzustellen.
-
Authentication-Header (Authentifizierungsinformation
für den Empfänger):
Wird zur Übertragung von fälschungssicherer
Unterschrift zur Authentifizierung des Senders genutzt.
 Abb. 1.3: Eine mögliche Verkettung von Erweiterungs-Headern
Abb. 1.3: Eine mögliche Verkettung von Erweiterungs-Headern
-
Encrypted security payload (Verschlüsselungsinformation
für den Empfänger):
Das ist immer der letzte der verketteten Header, der
teilweise noch im Klartext erscheint. Alle nachfolgenden Daten werden entsprechend
verschlüsselt.
-
Destination-Options-Header (weitere Optionen für
den Empfänger):
Vorgegeben werden nur die ersten zwei Felder dieses Headers:
nächster Header und Länge des Headers. Alle anderen Felder sowie
der Kontext werden von den Anwendungen bestimmt.
-
Header der oberen Schicht (ICMP, UDP,TCP, etc.).
1.2.2 Jumbo-Payload-Option
Der Jumbo-Payload-Option-Header ist der einzige bis jetzt
definierte Hop-by-Hop-Header. Diese Option wird für die Übertragung
von Datagrammen größer als 65 535 Byte. Das Format dieser Option
ist in der Abb. 1.4 gezeigt.
 Abb. 1.4: Der Jumbo-Payload-Option-Header
Abb. 1.4: Der Jumbo-Payload-Option-Header
Die ersten zwei Felder sind für die meisten Erweiterungs-Header
typisch: nächster Header und Länge des Headers. Es folgen der
Typ 194 und die Länge der Daten - 4 Byte. Das Feld »Jumbo-Payload
Länge« muß die Länge des zu übertragenden Datagramm,
d. h. einen Wert größer als 65 535 Byte, beinhalten (siehe auch
[RFC 2147]).
1.2.3 Source Routing
IPv6 adoptiert eine Reihe von Routing-Protokollen, wie RIP,
OSPF, BGP und CIDR. Zusätzlich kann der Routing-Header für Source-Routing
verwendet werden. Dabei werden eine oder mehrere Zwischenknoten (Router)
aufgelistet, über die das Datagramm geleitet wird. Das Format des
Routing-Headers ist in der Abb. 1.5 gegeben.
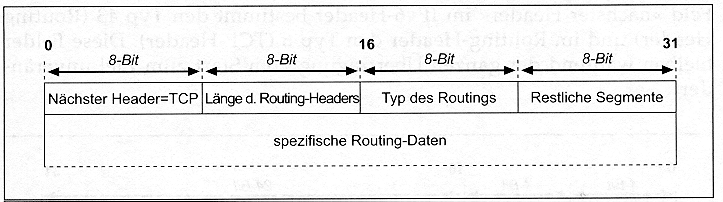 Abb. 1.5: Der Routing-Header
Abb. 1.5: Der Routing-Header
Zur Zeit wird nur der Routing-Mechanismus mit dem Typ
des Routing = 0 spezifiziert. Die spezifischen Routing Daten beinhalten
ein Feld starke oder schwache Abbildung und eine Liste von (maximal 24)
Router-Adressen, wobei die Adresse des nächsten Routers als Empfängeradresse
in den IP-Header eingetragen wird (Abb. 1.6).
Dieses Routing-Konzept stellt eine wesentliche Leistungsverbesserung
gegenüber dem IPv4-Source-Routing dar. Der Routing-Header wird nur
dann von einem Router bearbeitet, wenn er seine eigene Adresse im Empfängeradressenfeld
des IP-Headers erkennt. Er überprüft dann, ob weitere nachfolgende
Routeradressen in der Liste vorhanden sind:
-
Wenn keine weiteren Router eingetragen sind (d. h. das Feld
»restliche Segmente« in der Abb. 1.5 ist gleich 0),
handelt es sich um den Endknoten der Route, so daß mit der Bearbeitung
der nächsten Erweiterungs-Header fortgefahren wird.
-
Wenn weitere Router eingetragen sind, werden die nächste
Routeradresse aus der Liste mit der Empfängeradresse im IP-Header
ausgetauscht und das Datagramm weitergeleitet. Wenn das Bit 0 im Feld »starke
oder schwache Abbildung« in der Abb. 1.6 den Wert 1 hat (d. h.
eine starke Abbildung darstellt), muß diese Adresse eine Nachbaradresse
sein.
Zum Beispiel soll ein IPv6-Datagramm vom »Start«
zum »Ziel« über »Router 1«, »Router
2«, und »Router 3« geleitet werden. Abb. 1.6 zeigt die
Struktur des Routing-Headers als Überbau eines IPv6-Pakets (hell getönte
Felder). Nach Erreichen des ersten Routers (Abb. 1.6 zeigt den Zustand
nach Erreichen des zweiten Routers) mit IP-Adresse »Router l «
wird die Adresse des nächsten Routers mit IP-Adresse [1] mit der Empfängeradresse
im IP-Header ausgetauscht: der alte Inhalt in den Feldern »IP-Adresse«
[2] und »Empfängeradresse« wird mit neuem, fett markiertem
Inhalt versehen. Das Feld »restliche Segmente« wird um 1 verkleinert.
Das Feld »nächster Header« im IPv6-Header bestimmt den
Typ 43 (Routing Header) und im Routing-Header den Typ 6 (TCP-Header). Diese
Felder bleiben während der ganzen Übertragung vom Start zum Ziel
unverändert.
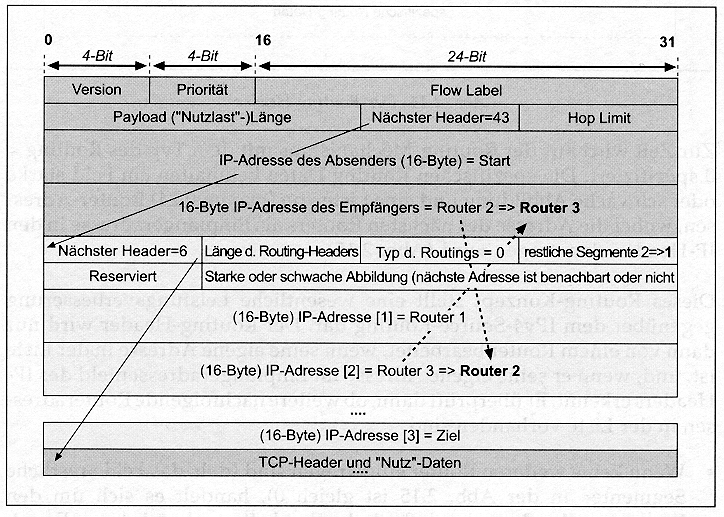
Abb. 1.6: Struktur des Routing-Headers als Überbau
eines IPv6-Pakets (hell getönte Felder). Nach Erreichen des zweiten
Routers mit IP-Adresse [1] wird die Adresse des nächsten Routers mit
IP-Adresse [2] als Empfängeradresse in den IP-Header eingetragen.
1.2.4 Fragmentierung
Eine Fragmentierung von IP-Datagrammen wird vorgenommen,
wenn eines der Netzsegmente auf der Route kleinere Pakete (sogenannte MTUs,
Maximum Transmission Unit) als das Datagramm übertragen kann,
so daß es zusätzlich in kleinere zusammenhängende Fragmente
aufgeteilt wird.
In IPv4 wird die Fragmentierung »automatisch«
von den Routern durchgeführt. Dieses »automatische« Herangehen
hat aber den Nachteil, daß jeder Router die Notwendigkeit der Fragmentierung
bei jedem Datagramm überprüfen muß. Wenn notwendig, sollen
dann die betroffenen Router die Fragmentierung und Defragmentierung, vielleicht
auch mehrfach, auf der Route vornehmen. Da der Sender und der Empfänger
auch mehrere Datagramme miteinander austauschen, wird diese Prozedur jedesmal
wiederholt.
Beim IPv6-Konzept ist nur eine Ende-zu-Ende-Fragmentierung
vorgesehen. Der Sender führt, falls notwendig, die Fragmentierung
eines Datagramms durch und übermittelt die entsprechende Information
an den Empfänger über den Fragment-Header. Der Fragment-Header
wird nicht von den Routern berücksichtigt, was eine wesentliche Vereinfachung
und Leistungsverbesserung gegenüber der IPv4 darstellt.
Der IPv6-Fragmentierungsalgorithmus ist einfach. Falls
ein Segment auf der Route Pakete dieser Länge nicht durchlassen kann,
wird das Paket annulliert und eine ICMP-Fehlermeldung »Packet Too
Big« zum Sender mit der Information über die erforderliche Länge
zurückgesendet. Der Sender führt dann die erforderliche Fragmentierung
durch, trägt sie in den Fragment-Header ein und sendet erneut das
Paket in Form von mehreren Datagrammen. Jedes Datagramm hat dann den gleichen
IPv6-Header, gefolgt von dem Fragment-Header, der das Fragment beschreibt
(Abb. 1.7). Für diesen Zweck wird ein 32-Bit-langer Identifikator
erzeugt, der die zusammenhängenden Datagramme mit den Fragmenten eindeutig
markiert. Jedes Fragment wird unabhängig geroutet.
 Abb. 1.7: Fragmentierung eines IP-Datagramms in
n Fragmente
Abb. 1.7: Fragmentierung eines IP-Datagramms in
n Fragmente
Der Fragment-Header ist in Abb. 1.8 dargestellt. In IPv6
erfolgt die Fragmentierung in den Bereichen von über 576 Byte langen
Paketen durch die Endknoten. Bei unterliegenden Netzen, die kleinere Pakete
als 576 Byte erfordern, wie etwa ATM, sollte die erforderliche Fragmentierung
auf der
 Abb. 1.8: Der Fragment-Header
Abb. 1.8: Der Fragment-Header
Link-Schicht erfolgen. IPv6-Datagramme dürfen die
576 Byte Grenze nicht unterschreiten. Das Feld »Offset des Fragments«
gibt den Offset der Daten in diesem Datagramm bezüglich des Anfangs
der fragmentierten Nutzdaten in Byte an. Das letzte Bit M markiert (bei
M=l) das letzte Fragment.
1.2.5 Path MTU Discovery
Oft wird eine Fragmentierung umgangen, indem die obere Schicht,
die für die Aufteilung in Pakete verantwortlich ist (z. B. TCP, NFS),
sich an die maximal zulässige MTU entlang der Route anpaßt.
Dieses wird »Path MTU Discovery« genannt und wird sowohl bei
Unicast- als auch für Multicast-Adressen auf der Basis der ICMP-Fehlermeldung
»Packet Too Big«durchgeführt [RFC
1981]. Dadurch wird weiterhin gesichert, daß die Paketlänge
aus der oberen Schicht mit der maximal möglichen MTU auf der Route
erzeugt wird, was zur Erhöhung der Effektivität beiträgt.
Da sich die zulässige MTU der Route dynamisch vergrößern
kann, wird periodisch der Versuch unternommen, Pakete mit größeren
MTU zu verschicken, um dies zu entdecken. Deshalb muß die IPv6-Schicht
die UDP/TCP Schicht über Veränderungen in der MTU entlang der
Route informieren.
2. Sicherheitskonzepte des neuen Internet-Protokolls IPv6
Die Sicherheitsdienste beim IPv6 werden durch zwei getrennte
Header gesichert:
-
IP-Authentication-Header (AH)
sichert Integrität und Authentizität, ohne Vertraulichkeit (siehe
Abschnitt 2.2) der IP-Datagramme, ausgetauscht zwischen zwei oder mehreren
Stationen und Routern. Eine Vertraulichkeit über Verschlüsselung
wird hier nicht vorgesehen, damit man die Einschränkungen mancher
Länder für Export (USA) oder Verwendung (z. B. Frankreich) von
bestimmten Verschlüsselungsverfahren nicht verletzt. Der Router mit
einer AH-Implementierung kann dabei einen Sicherheits-Gateway zu einer
Sicherheitszone darstellen.
-
IP-Encapsulating Security Payload (ESP)
sichert Integrität, Authentizität und Vertraulichkeit der IP-Datagramme,
die zwischen zwei oder mehreren Stationen und Routern ausgetauscht werden.
Eine verschlüsselte Kommunikation zwischen zwei Gateways könnte
zur Verbindung von zwei Sicherheitsinseln verwendet werden. Dies schließt
aber die gleichzeitige Verwendung einer Station-zu-Station-Verschlüsselung
nicht aus. Der Router mit einer ESP-Implementierung kann dabei einen Sicherheits-Gateway
zu einer Sicherheitszone darstellen. Wenn in einer verschlüsselten
Ende-zu-Ende-Kommunikation die Router die Verschlüsselung nicht unterstützen,
kann man nur den Inhalt des Datagramms, z. B. die TCP/UDP-Pakete, verschlüsseln.
Die beiden Sicherungsmechanismen können getrennt oder
gemeinsam genutzt werden.
2.1 Sicherheitsassoziationen
Eine Sicherheitsassoziation wird durch die Kombination eines
Security Parameter Index (SPI) und der Empfängeradresse eindeutig
identifiziert. Sie ist auch eine Voraussetzung für die Nutzung von
IP-Authentication-Header (AH) und/oder IP-Encapsulating Security Payload
(ESP). Die Parameter zum SPI einer Sicherheitsassoziation sind folgende:
-
Authentifizierungsalgorithmus und sein Modus für den
IP-Authentication-Header (AH)
-
Schlüssel für den Authentifizierungsalgorithmus
für den IP-Authentication-Header (AH)
-
Verschlüsselungsalgorithmus, sein Modus und »Transform«
für die IP-Encapsulating Security Payload (ESP). Ein »Transform«
ist in diesem Fall die opake Datentabelle, die bei der Verschlüsselung
genutzt wird.
-
Schlüssel für den Verschlüsselungsalgorithmus
für die IP-Encapsulating Security Payload (ESP)
-
Präsenz einer kryptographischen Synchronisation oder
eines Initialisierungsvektors (IV) für die IP-Encapsulating Security
Payload (ESP)
-
Authentifizierungsalgorithmus und sein Modus für den
ESP-Transform (falls vorhanden)
-
Authentifizierungsschlüssel für den ESP-Transform
(falls vorhanden)
-
Lebensdauer der Schlüssel
-
Lebensdauer der Sicherheitsassoziation
-
Senderadresse der Sicherheitsassoziation
-
Sensibilitätsebene, z. B. »streng geheim«,
»geheim« oder »unbestimmt«, um mehrere Sicherheitsebenen
zu erlauben.
Der Sender wählt die Sicherheitsassoziation (identifiziert
durch den SPI) auf der Grundlage des Anwenderidentifikators und der Empfängeradresse.
Die Empfängeradresse kann auch eine Multicast-Gruppenadresse sein.
Der Empfänger identifiziert die Sicherheitsassoziation
durch den SPI und die Empfängeradresse. Auf dieser Basis werden alle
ankommenden Pakete ausgewertet und verarbeitet. Mehrere Sender einer Multicast-Gruppe
können eine einzige Sicherheitsassoziation zum Empfänger nutzen.
Dann kann der Empfänger zwar nicht eindeutig den Sender identifizieren,
er weiß nur, daß er die Sicherheitsassoziation der Multicastgruppe
kennt. Der Empfänger kann weiterhin den Sender aus der Multicastgruppe
nicht authentifizieren, wenn symmetrische Verschlüsselungsverfahren
genutzt werden. Eine Authentifizierung durch die Sicherheitsassoziation
kann dann erfolgen, wenn jeder der Sender seine eigene Sicherheitsassoziation
startet und dabei asymmetrische Verschlüsselungsverfahren nutzt.
Eine Sicherheitsassoziation ist immer unidirektional.
Eine Sitzung zwischen zwei Stationen muß dementsprechend zwei Sicherheitsassoziationen
verwalten - für jede Richtung eine. Sie bemerken, daß ähnlich
wie die asymmetrischen Verschlüsselungssysteme, der Empfänger
der Initiator einer Sicherheitsassoziation ist, d. h. er wählt die
SPI auf der Basis der Empfänger-Unicastadresse oder seiner Multicastgruppe.
2.2 IP-Authentication-Header
Der IP-Authentication-Header (AH) [RFC
1826] beinhaltet Information, die zur Authentifizierung des IP-Datagramms
dient. Für diesen Zweck wird eine verschlüsselte Signatur über
das ganze Datagramm mit einem geheimen Schlüssel berechnet. Bestimmte
Felder, die in den Routern verändert werden (z. B. »Hop Limit
bei IPv6«, »TTL« und »Header Checksum bei IPv4«,
»ident«, »fragment offset« und »routing pointer«)
werden bei dieser Berechnung nicht berücksichtigt. Der regelmäßige
Empfänger kann diese Signatur entschlüsseln und dadurch die Integrität
und die Authentizität der Nachricht feststellen. Um eine Rückwärtskompatibilität
zu den älteren Systemen ohne Authentication-Header-Unterstützung
zu sichern, wird die Signatur ins eigene Feld übertragen. Die älteren
Systeme können dann diese Daten ignorieren.
Der Authentication-Header befindet sich normalerweise
bei IPv6-Datagrammen nach dem Fragmentation-Header und vor den ESP und
dem Header der Transportebene (siehe Abschnitt 1.2.1). Bei den IPv4-Datagrammen
wird der Authentication-Header gleich nach dem IPv4-Header plaziert.
 Abb. 2.1: Authentication-Header
Abb. 2.1: Authentication-Header
Das Format des Authentication-Headers ist in der Abb.
2.1 gegeben. Das Feld »nächster Header« bestimmt
den Typ des nächsten Header nach AH, entsprechend der von IANA zugewiesenen
Nummern [RFC 1700].
Die Länge des AH wird als Anzahl von 32-Bit-Worten
angegeben.
Der Security Parameter Index (SPI) stellt einen
Identifikator der Sicherheitsassoziation dieses Datagramms dar.
Das Feld »Authentication
Data« wird durch die Authentification Transform berechnet und
wird hier allgemein Signatur genannt. Es wird entweder durch einen Message-Digest-Algorithmus
(z. B. MD5) oder andere Hash-Algorithmen berechnet.
Bei der Verschlüsselung der Signatur können
symmetrische und asymmetrische Verschlüsselungsverfahren verwendet
werden. Dabei ist bei IPv6 keine direkte Nutzung von Schlüsselservern
(KDC) vorgesehen. Dieses ergibt folgende zwei Szenarien:
1. Verschlüsselung der Signatur über symmetrischen
Schlüssel:
Zu dieser Gruppe gehört auch das Default-Verfahren
für IPv6 MD5 mit einem 128-Bit-langen Schlüssel.
2. Verschlüsselung der Signatur über
asymmetrischen Schlüssel:
Zum Beispiel können bei den asymmetrischen Verschlüsselungsverfahren
die beiden Schlüssel für Authentifizierung und Nichtwiderrufbarkeit
einer Nachricht vom A nach B benutzt werden:
-
Der Sender einer Nachricht nutzt seinen geheimen Schlüssel,
um die Signatur zu verschlüsseln
-
Der Empfänger nutzt den entsprechenden öffentlichen
Schlüssel, um die Signatur zu entschlüsseln und danach zu überprüfen.
Dadurch wird die Integrität der Daten, die Authentizität der
Nachricht nachgewiesen.
-
Voraussetzung dafür ist es, daß der öffentliche
Schlüssel durch IPRA zertifiziert ist. Andererseits könnte ein
Eindringling dem Empfänger einen öffentlichen Schlüssel
im Namen des regelmäßigen Senders zur Verfügung stellen
(Spoofing).
Es ist zu erwarten, daß die Nutzung des Authentication-Headers
mit einem relativ großem Aufwand für die Verschlüsselung
jedes Datagramms und dadurch zur wesentlichen Verlangsamung der Internet-Kommunikation
führen wird. Deshalb wird empfohlen, ihn vorwiegend in den Stationen
(Endknoten) und nicht in den Gateways zu nutzen.
Der Sender berechnet die Signatur über das Datagramm,
so wie es bei dem Empfänger erscheinen soll. Die Felder, die während
der Übertragung verändert oder zusätzlich angehängt
werden, werden bei der Berechnung durch Nullen ersetzt.
Ein Problem bei der Nutzung des Authentication-Headers
ist die Behandlung von ICMP-Fehlermeldungen, die als Inhalt die originale
Nachricht, aber nicht unbedingt die ganze Nachricht einschließen.
Im zweiten Fall wäre eine Authentifizierungsüberprüfung
nicht möglich. Der Empfänger einer solchen ICMP-Nachricht kann
sie entweder verarbeiten, d. h. ihr vertrauen mit den möglichen Sicherheitskonsequenzen
oder ihr nicht vertrauen und demzufolge die ICMP-Nachricht nicht berücksichtigen.
Dieses Problem hat vorläufig keine allgemeine Lösung.
Ein anderes Sicherheitsproblem stellt das Source-Routing
dar. IP-Spoofing ist hier ohne weiteres möglich. Eine sehr aufwendige
Lösung scheint hier, jedes über Source-Routing empfangene Paket
über separate Authentication Headers zu überprüfen.
2.3 IP-Encapsulating Security Payload
Der IP-Encapsulating Security Payload (ESP) sichert Integrität,
Authentizität und Vertraulichkeit der IP-Datagramme, indem entweder
das ganze IP-Datagramm, d. h. dessen Nutzlast (Payload), oder nur die Pakete
der Transportschicht (UDP oder TCP) in ein ESP eingekapselt werden. Der
ESP wird dann verschlüsselt. Im ersten Fall spricht man von einem
Tunnel-Modus, im zweiten von einem Transport-Modus.
Im Tunnel-Modus bildet das originale Datagramm
den verschlüsselten Teil von ESP, wobei der ganze ESP dann über
ein Datagramm mit unverschlüsseltem Header übertragen wird.
Im Transport-Modus wird
ein ESP-Header direkt nach dem IP-SchichtHeader (d. h. vor dem TCP-, UDP-
oder ICMP-Header) plaziert (Abb. 2.2). Die IP-Header
oder die Optionen werden demzufolge nicht verschlüsselt.
Die Verschlüsselung erfolgt auf der Basis eines Schlüssels,
der auf der Basis eines Key-Management-Mechanismus (oder KDC) vor der Verschlüsselung
vereinbart werden soll. Falls der Empfänger über keinen Schlüssel
für diese Sicherheitssitzung verfügt, wird die verschlüsselte
ESP annulliert und der Fehler in einem Log gespeichert. Der Empfänger
antwortet nicht mit einer Fehlermeldung, um eine Dienstblockade seitens
eines Eindringlings zu umgehen.
Wenn zwei Stationen ESP direkt implementieren und sie
zueinander Link-lokal sind (es wird kein Router benötigt), wird der
Transportmodus empfohlen, der einen wesentlich kleineren Aufwand für
die Verschlüsselung und Entschlüsselung benötigt.
Am ESP kann weiterhin ein IP-Pseudo-Header angehängt
werden, der im Klartext übertragen und von den Routern wie ein normaler
IP-Header interpretiert wird. ESP kann zwischen Stationen, einer Station
und einem Router (Sicherheitsrouter) oder zwischen zwei Routern betrieben
werden. Die Nutzung von ESP ist immer mit einer Leistungsminderung verbunden,
die von der konkreten Implementierung, von dem verwendeten Verschlüsselungsverfahren
und von der Länge des Schlüssels abhängt. ESP überläßt
die Wahl des Verschlüsselungssystems den Anwendern. Alle Systeme im
Internet müssen allerdings DES mit CBC (Cipher Block Chaining) unterstützen.
 Abb. 2.2: Verschlüsselung durch den ESP-Header
im Transportmodus
Abb. 2.2: Verschlüsselung durch den ESP-Header
im Transportmodus
Das Feld »Security Parameter
Index (SPI)« in der Abb. 2.3 identifiziert eindeutig die
Sicherheitsassoziation. Der konkrete Wert von SPI wird zufällig bestimmt,
wobei die Werte 0000000116 bis 000000FF16 für
IANA reserviert sind.
Das Feld »Opaque
Transform Data« hängt vom konkreten Verschlüsselungsverfahren
ab. Das Format des Feldes für das obligatorische ESP DES-CBC (Data
Encryption Standard Cipher Block Chaining) [RFC
1829] ist in der Abb. 2.4 gegeben.
Das Feld »VI«
beinhaltet dabei die Anfangsdaten für die XOR-Operation mit dem ersten
über DES verschlüsselten Datenblock.
Das Feld »Payload
Data« sind die zu verschlüsselnden Daten, deren Typ
im Feld »Payload Type«
spezifiziert wird. Wenn z. B. der ESP-Tunnel-Mode eingesetzt wird, beinhaltet
Payload Data das ganze IP-Datagramm und das Feld »Payload Type«
hat den Wert 4 (IP-in-IP-encapsulation).
Das Feld »Padding«
beinhaltet Füllbits für die Payload, dahinter wird die Länge
des Paddings definiert..
Die kombinierte Verwendung von ESP und AH ist zulässig
und für die Fälle erforderlich, bei denen Integrität, Authentizität,
Vertraulichkeit und Nichtwiderrufbarkeit der IP-Datagramme gesichert werden
sollen. In diesem Fall wird zuerst ein Authentication Header eingefügt,
dessen Platz festlegt, welcher Teil des IP-Datagramms authentifiziert wird.
Erst dann wird das Datagramm über ESP verschlüsselt.
 Abb. 2.3: Der ESP-Header
Abb. 2.3: Der ESP-Header
 Abb. 2.4: Format des Feldes Opaque Transform Data
Abb. 2.4: Format des Feldes Opaque Transform Data
Jürgen Poiger, 16.07.1998