
Die Daten
Unter Reproduktionszahl R verstehen wir die Anzahl derjenigen, die im Mittel von einem Infizierten infiziert werden. Die Intuition spielt uns hier einen Streich: Die Bedeutung ist uns sofort klar und wir meinen, die Verlautbarungen der Wissenschaftler und Politiker verstanden zu haben: R < 1 heißt, die Zahl der Infektionen geht zurück, die Pandemie erstirbt; bei einem R > 1 hingegen droht exponentielles Wachstum und mit ihm die Katastrophe. Jetzt kommen beruhigende Nachrichten: Die Reproduktionszahlen waren bereits vor dem Shutdown am Sinken. Dies zeigt die folgende Grafik, die ich aus den Daten des Robert Koch Instituts gewonnen habe.
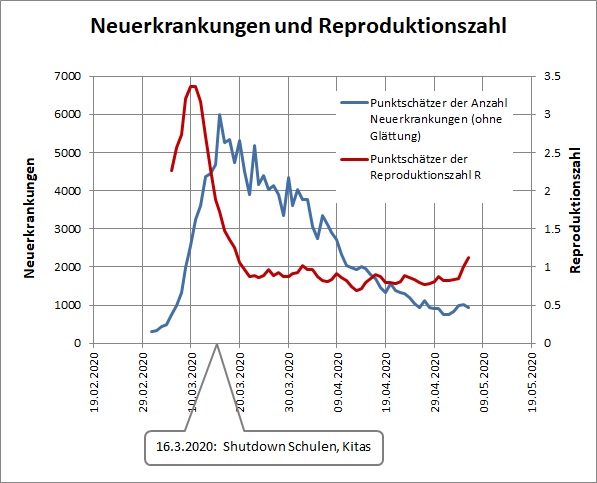
Und sogleich wird die Begründung nachgeschoben: Nach den alarmierenden Nachrichten aus Japan und Österreich haben sich die Deutschen sofort vernünftig verhalten und von sich aus die sozialen Kontakte reduziert. Ich werde nun ein wenig Wasser in den Wein tun.
Kennzahlen
In den Kommentaren zum letzten Artikel habe ich ein paar Bemerkungen zu den Kennzahlen gemacht. Ich wiederhole kurz das Wesentliche: Die Reproduktionszahl sagt uns über die Dynamik der Virenausbreitung erst dann etwas, wenn wir auch die Generationszeit, den Generationenabstand, kennen. Das RKI hat in letzter Zeit die Generationszeit aus einer Plausibilitätsbetrachtung gewonnen und zunächst auf drei Tage festgelegt. Seit kurzem gilt eine Generationszeit von vier Tagen, was die Schwankungsbreite und damit die Unschärfe der Schätzung etwas verringert. In die Formel zur Schätzung der Reproduktionszahl nach dem RKI-Verfahren geht die angenommene Generationszeit ein. Die geschätzte Reproduktionszahl ist folglich parameterabhängig und bestenfalls zufällig gleich der tatsächlichen.
Das RKI gibt einen Schätzwert für die Reproduktionszahl an, der die Krankmeldungen der vergangenen 3 Tage auf diejenigen der davor liegenden 3 Tage bezieht. (Neuerdings nimmt man 4 Tage anstelle der 3.) Dabei wird stillschweigend vorausgesetzt, dass die Neuerkrankungen von den Erkrankten der vorhergehenden Generation ausgehen – bei einer angenommenen Generationszeit von 3 bzw. 4 Tagen.
Aber Achtung: Gerade in der Anfangsphase erfasst das RKI die Erkrankungsquellen nur unzureichend. Sie befinden sich zum Großteil im Ausland: Urlauber und Geschäftsreisende schleppen das Virus ein. Im Quotienten Neuerkrankte der letzten 3 oder 4 Tage geteilt durch die Erkrankten der davor liegenden 3 oder 4 Tage wird meines Erachtens der Nenner zumindest zu Beginn weit unterschätzt. Möglicherweise gab es überhaupt kein Absinken der Reproduktionszahl und sie lag von Anfang an bei etwa 1.
RKI-Bashing ist nicht geboten
Die niedrigen Reproduktionszahlen seit Anbeginn des Shutdowns, also noch bevor der Shutdown seine Wirkung entfalten konnte, berechtigen zur Kritik an der Shutdown-Politik. Das Volk entrüstet sich. Eine sonderbare Melange aus Systemgegnern von ganz rechts bis ganz links, eine Querfront, geht zu den Hygiene-Demos auf die Straße; das Ganze wird gewürzt von Verschwörungstheoretikern aller Färbungen. Die einen meinen, Bill und Melinda Gates wollten die Gesundheitssysteme der Welt kapern, um ihre Vorstellungen vom Wohl und Wehe der ganzen Welt aufzuzwingen; wieder andere wissen von einer Geheimgesellschaft, die auf die Neue Weltordnung hinwirkt, wie sie in den Georgia Guidestones angekündigt worden ist.
Diese Leute melden sich lautstark zu Wort, und die als Lügenpresse diffamierten Medien treten den Rückzug an. Peinlich war die Heute-Sendung des ZDF vom 10. Mai; sie machte einen Sündenbock aus und schob dem Robert Koch Institut die Schuld an der Berichterstattung der letzten Zeit zu: Es habe widersprüchliche Aussagen veröffentlicht und mit wechselnden Kennzahlen zur Verwirrung beigetragen.
Hätte die Redaktion doch vorher besser aufgepasst; sie hätte einen Sündenbock nicht nötig gehabt. Ich jedenfalls werde mich an diesem RKI-Bashing nicht beteiligen. Zum Auftrag des Instituts gehört es, epidemiologische Daten zu erfassen, diese mit Mitteln der beschreibenden und schließenden Statistik aufzubereiten und zu veröffentlichen.
Fragwürdig und zu kritisieren ist die tendenziöse Interpretation des Zahlenwerks durch Interessengruppen und Verschwörungstheoretiker. Leider beteiligen sich auch angesehene Fachleute, Epidemiologen und Virologen, an diesem Spiel. Es wird zuweilen mehr in die Statistiken hineininterpretiert, als sie hergeben. Dem RKI kann man vorwerfen, gegen diese Unsitte nicht deutlich genug in Stellung gegangen zu sein.
Der Leichtgläubige wird leicht zum Opfer seiner Autoritätshörigkeit. Aber grundsätzlich gibt es einen Ausweg: das genaue Studium der Daten und die korrekte Interpretation der Kennzahlen. Soweit ich sehen kann, stellt das RKI alle dafür notwendigen Informationen zur Verfügung. Ich habe in diesem Artikel, die Fakten betreffend, ausschließlich auf Publikationen des Robert Koch Instituts zurückgegriffen.
Publikationen des Robert Koch Instituts
Tabelle mit Nowcasting-Zahlen zur R-Schätzung (10.5.2020, Tabelle wird täglich aktualisiert) (xlsx, 12 KB, Datei ist nicht barrierefrei)
https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Projekte_RKI/R-Beispielrechnung.xlsx?__blob=publicationFile
Täglicher Lagebericht des RKI zur Coronavirus-Krankheit-2019 (COVID-19) 30.04.2020 AKTUALISIERTER STAND FÜR DEUTSCHLAND:
https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Situationsberichte/2020-04-07-de.pdf?__blob=publicationFile
AKTUELLE DATEN UND INFORMATIONEN ZU INFEKTIONSKRANKHEITEN UND PUBLIC HEALTH. Epidemiologisches Bulletin 17/2020
https://www.rki.de/DE/Content/Infekt/EpidBull/Archiv/2020/Ausgaben/17_20.html
Ein weiterer Faktor, der einen gewissen Einfluss auf die statistische Beschreibung der Epidemie haben wird, ist die Anzahl der durchgeführten Tests. Denn logischerweise wird eine Erkrankung nur registriert, wenn ein Test sie bestätigt, und gerade am Anfang der epidemischen Entwicklung kann es sein, dass die Testkapazität ein limitierender Faktor ist. Das heißt, die Anzahl der neu Erkrankten wird zu Beginn stark unterschätzt. Im Lauf der Zeit bessert sich die Situation und der Anteil der nicht erkannten Neu-Erkrankungen geht zurück. Das Ergebnis wäre, dass die Reproduktionszahl am Anfang überschätzt würde.
Sicher gibt es viele unterschiedliche Schätzungen der Dunkelziffer und dementsprechend „korrigierte“ Berechnungen der Reproduktionsrate, aber die relative Unsicherheit wird beim Teilen zweier nicht exakt bekannter Größen natürlich enorm.
Wenn ich mich recht erinnere, kursierten erste Schätzungen eines Basis-Reproduktionsfaktors um 3 bereits, als die westliche Welt noch hoffte, Covid-19 würde China nicht verlassen. Beim ersten Krankheitsausbruch in Wuhan dürften „importierte Fälle“ aber keine Rolle gespielt haben.
Wir sind uns sicher darüber einig, dass die Basisreproduktionszahl nicht eine dem Virus eigene Kennzahl ist. Die Gesellschaft und deren Kontaktgepflogenheiten sind wesentliche Einflussfaktoren. Der Basisreduktionsfaktor Wuhans lässt sich also nicht ohne Weiteres auf Deutschland übertragen. Auch die staatlich verordneten Quarantänemaßnahmen Chinas sind mit dem Shutdown hierzulande kaum zu vergleichen. Es muss nicht verwundern, dass die Reproduktionsrate in China drastisch zurückgegangen ist. Ein vom Menschen verursachter Virenimport ist kein passendes Erklärungsmodell für den Effekt.
„Möglicherweise gab es überhaupt kein Absinken der Reproduktionszahl und sie lag von Anfang an bei etwa 1.“ Ich fürchte, diese Vermutung kann durch die Einzelheiten der Ausbreitung widerlegt werden. Eine Reproduktionszahl von ungefähr 1 auch in der heißen Phase im März würde ja heißen, dass ungefähr so viele Infizierte eingeflogen sind, wie wenige Tage später erkrankten. Das ist vollkommen unplausibel. In einem solchen Szenario hätten sich die Erkrankungen viel gleichmäßiger verteilen müssen. Eine Jumbo-Ladung voll Infizierter aus China landet in Frankfurt – so weit noch denkbar. Aber dann hätte es lauter Ausbrüche in den Heimatorten der Reisenden geben müssen. Stattdessen gab es erkennbare Einzelereignisse, bei denen sich viele Leute auf einmal angesteckt haben: die Karnevalsveranstaltung in Gangelt, das Starkbierfest in (weiß nicht mehr wo, Niederbayern), die Après-Ski-Bar in Ischgl.
Für den „Patient null“, der eines dieser Ereignisse ausgelöst hat, mag das R einen aberwitzig hohen Wert angenommen haben: irgendwo im dreistelligen Bereich. Bei der Durchschnittsbildung mischt sich dieser hohe Wert mit dem Wert R=0 für alle Infizierten, die sich rechtzeitig weggesperrt haben, und sonst noch allerlei Werten, und heraus kommt irgendetwas in der Größenordnung von 3. Wenn man das zu interpretieren versucht, gerät man sehr schnell an Grenzen. Ja, in der frühen Phase wurde die Verdoppelung der registrierten Infiziertenzahlen alle drei Tage mit beängstigender Genauigkeit eingehalten, was für einen konstanten R-Wert spricht. (Welche Konstante? Das hängt wiederum von der Generationsdauer ab, aber darauf kommt’s hier nicht an.) Demnach wären die explosiven Ausbruchsereignisse mit einer einigermaßen gleichbleibenden Rate eingetreten, so dass das Gesetz der großen Zahlen seine Wirkung hätte entfalten können. Angesichts der geringen Zahl dieser Ereignisse ist das eine eher wacklige Vermutung.
Und wenn diese Zahl gar nicht so gering wäre, wir aber andere, vielleicht kleinere und häufigere Ereignisse nicht richtig mitgekriegt hätten? Dafür sehe ich im Moment eigentlich keine Anhaltspunkte.
Na gut – in der Reproduktionszahl um die 3 mischen sich die natürlichen Eigenschaften des Virus mit den gesellschaftlichen Verhältnissen, zu denen bis zu diesem Zeitpunkt eben auch Massenveranstaltungen mit körperlicher Nähe zählten.
Man liest immer wieder ein anderes Argument: Der starke Anstieg der registrierten Infiziertenzahlen sei ein Artefakt, der durch den zeitgleichen starken Anstieg der Testzahlen zu erklären sei: Wer mehr sucht, findet auch mehr. Ich halte das Argument für nicht zutreffend. Denn soweit ich weiß, sind während dieser Zeit die Kriterien dafür, wer überhaupt getestet wird, nicht geändert worden. Und es stand auch nichts davon in der Zeitung, dass die Testkapazitäten für die, die nach diesen (ziemlich engen) Kriterien zum Test zugelassen wurden, nicht ausgereicht hätten. Also hat man nicht etwa deswegen mehr gefunden, weil man eine größere Zufallsauswahl aus demselben Kollektiv getroffen hätte, sondern weil es mehr zu suchen gab.
Ärgerlich: Ich kann diese meine Vermutung nicht belegen. Über die Einzelheiten mit den Testkapazitäten findet man irgendwie nichts in öffentlichen Quellen. Und das Bild, das ich aus der lokalen Tageszeitung gewonnen habe, muss ja nicht vollständig sein.
Die Anzahl der Proben kann man beispielhaft für Bayern in folgd. Diagramm im unteren Bereich der Webseite sehen:
https://www.lgl.bayern.de/gesundheit/infektionsschutz/infektionskrankheiten_a_z/coronavirus/karte_coronavirus/index.htm
Neben einer (geringen) Steigerung der Probennahme haben zusätzlich die Auswahlkriterien einen stärkeren Einfluss. Diese wurden jüngst geändert, sodass weitere Kurvenverläufe nur zum Teil mit den bisherigen Daten vergleichbar sein könnten.
Zur Ausbreitung in Clustern eignet sich folgende 2 Beispiele:
1. Ein Cluster A bildete sich in Wien von einem einzelnen Infizierten zu insgesamt 61 Fällen. Die Rückverfolgung ergab 6 Folgegenerationen, die mittels Quarantäne eingedämmt werden konnten. Die Reproduktionszahl war hier trotz Rückverfolgung und Quarantäne bei ca. 1,7 (grob geschätzt). Dies ist offensichtlich alarmierend.
2. Gegenübergestellt sei die Infektionskette in den Haushalten von Gangelt (starke Ausgangsbeschränkung, allerdings auch durch die hohe Prävalenz von 15% auch ein erhöhtes Risiko zum Virus-Fremdeintrag in einen Haushalt): Mit zunehmender Personenzahl nahm das Infektionsrisiko durch einen Infizierten im Haushalt für die weiteren Haushaltsmitglieder von 44% (2 Personen) auf 18% (4 Personen-Haushalt) hin ab. Entweder ist das Virus nicht so „enorm“ ansteckend, oder es ist nicht jeder rezeptiv. Ich denke ersteres ist der Fall: Das Ansteckungsrisiko kann durch geringe Verhaltensänderung bereits deutlich reduziert werden. Dies bestimmt dann den weiteren Verlauf der Ausbreitung und damit die Reproduktionszahl.
Besonders erstaunlich an der derzeitigen Ausbreitung finde ich, dass die sehr niedrige Zahl an Neuinfektionen eine Eindämmung möglich erscheinen lässt. Doch auch dazu gehen die Meinungen unter Fachleuten auseinander.
Aus all dem ziehe ich den Schluss, dass mittelnde Kennzahlen wie die Reproduktionszahl Sondereinflüsse nicht angemessen erfassen und abbilden können. Das lädt zu Fehldeutungen der Verlaufskurven ein. Einige der Sondereinflüsse werden oben genannt: der Virenimport, die Ausweitung der Testaktivitäten und die örtlich und zeitlich konzentrierten Massenveranstaltungen. Also: Vorsicht!
Sie haben schön gezeigt, wie groß der Einfluss gewisser Parameter auf das Ergebnis ist.
Genauso medienwirksam wie die Kennzahlen veröffentlicht werden, sollten daher auch die statistischen Unsicherheiten veröffentlicht werden. Ohne diese ist das Ergebnis doch mehr oder weniger wertlos und für die breite Masse nicht interpretierbar, bzw. wird auch mal schnell falsch interpretiert.